If you are working in the Data Science domain, then you are already familiar with Jupyter Notebook. It’s one of the most popular interactive tools to develop ML projects in Python. But you can also configure your Jupyter Notebook to run Scala and Spark with some easy steps.
Steps to set Jupyter Notebook to run Scala and Spark.
- Prerequisites:
1. Make sure that JRE is available in your machine and it’s added to the PATH environment variable. In my system Java Home is: C:\Program Files\Java\jre1.8.0_281
2. Anaconda is installed in your system.
3. If you just want to run Scala codes, then above prerequisites are enough. If you want to use Spark as well, then make sure that Spark is installed in your system.
I’ll create a different tutorial on how to install Spark on a Windows system and will link that post here. - Install spylon-kernal package
Open your Anaconda Powershell and run the command below.
pip install spylon-kernal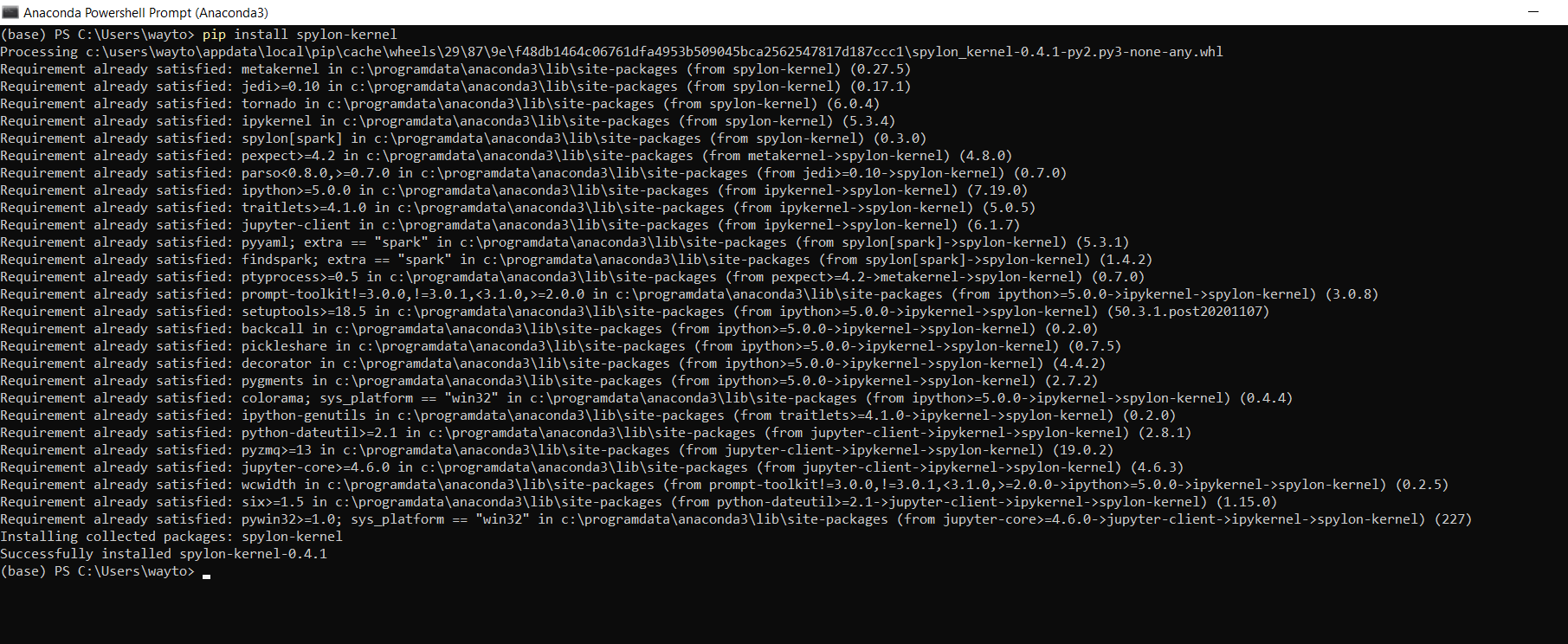
- Install Jupyter kernal
Use the command below to install Jupyter kernel. If you face any permission issue, then re-launch the Anaconda Powershell as Administrator.
python -m spylon_kernel install
- Launch Jupyter Notebook
Launch Jupyter notebook, then click on New and select spylon-kernel.
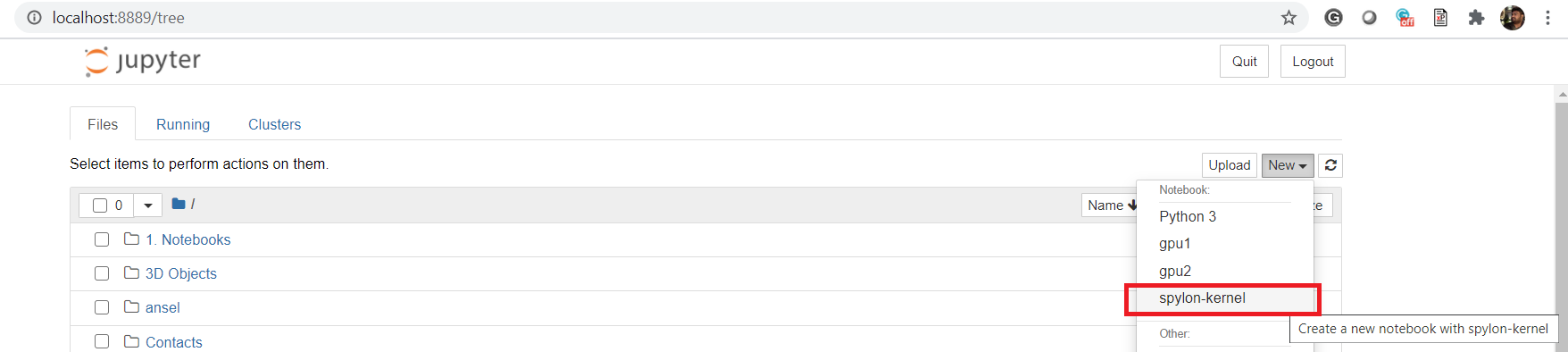
- Run basic Scala codes
You can see some of the basic Scala codes, running on Jupyter.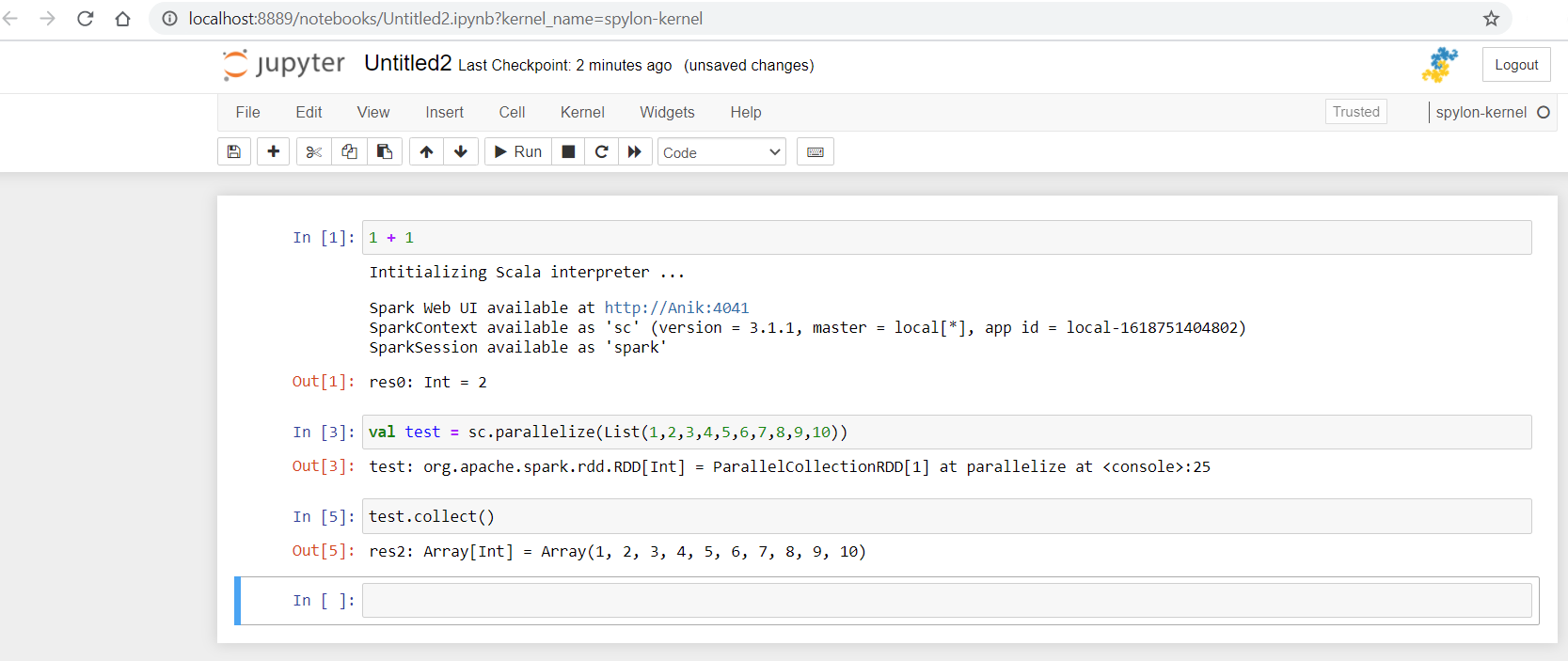
- Spark with Scala code:
Now, using Spark with Scala on Jupyter:
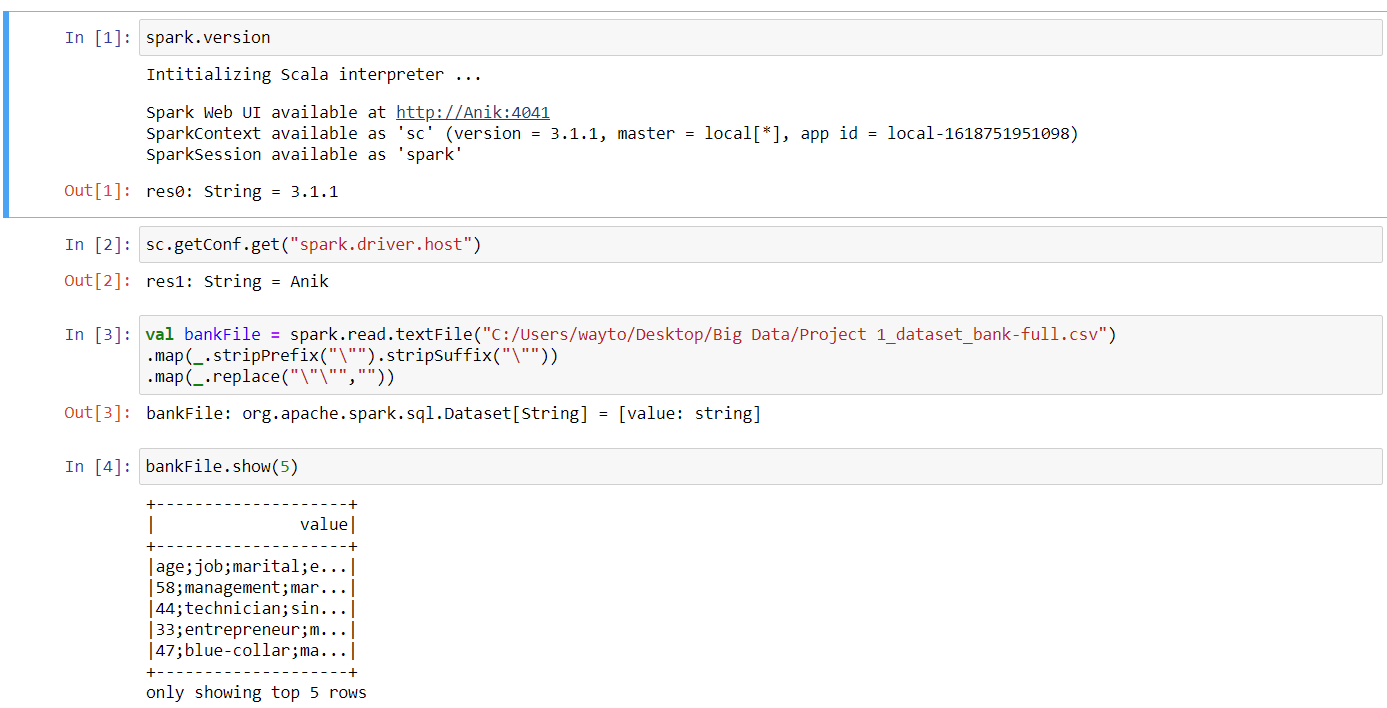
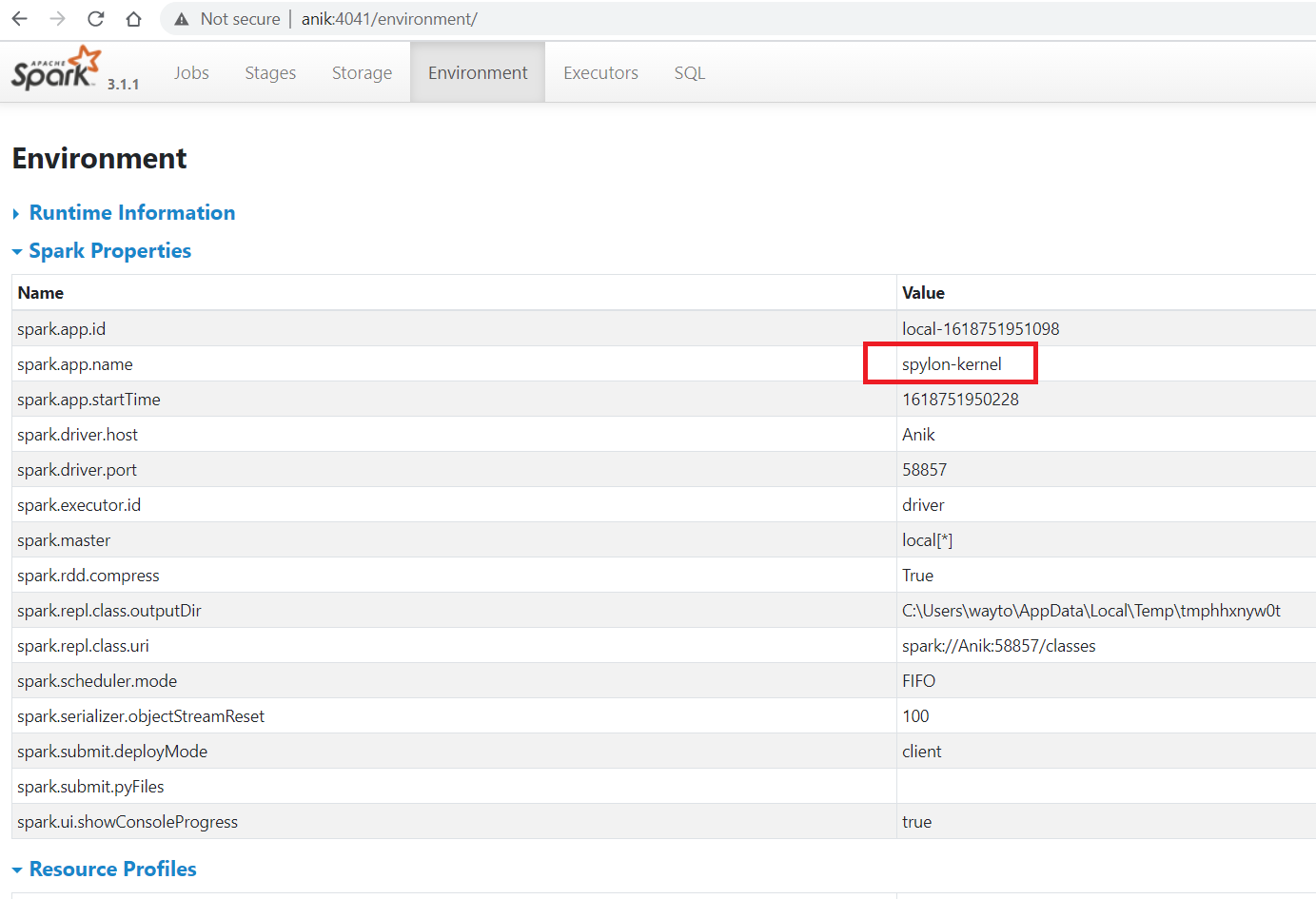
- Check Spark Web UI
It can be seen that Spark Web UI is available on port 4041. In Web UI go to Environment tab and you can see the below details.